Blog • Insights
Drupal, Referential Integrity, and You
First off: shame on you. Look at the mess you’ve made! Erm, well… I should probably back up and explain exactly what happened and why it’s bad. Hope you like whirlwind tours!
An Extremely Brief And Wholly Insufficient Introduction to Databases and the Relational Model
To most users, the database and its tables are not unlike the human gut microbiome: not something you even need to think about very often, but without it, you’d be in rather terrible shape. It requires a team effort.
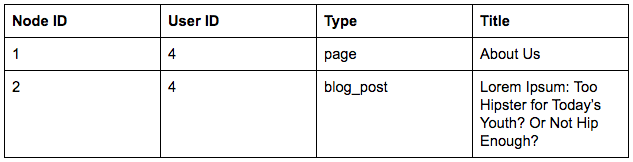
Here’s a pretend version of Drupal’s own “node” database table:

The terminology is exactly what you’d use to describe the table above:
- Row — One “unit” of data. Drupal identifies almost all rows with an ID. The example above has two rows: the page called “About Us” and the blog post.
- Column — There are three in the example: “ID”, “Type”, and “Title”. Logically, these are associated bits of data. Nodes have types and titles, users have email addresses and passwords, and so forth.
Most Drupal tables assign an ID column, which is required to be unique. For code, this is fairly logical — there’s an easy way to point out “this node” or “this user.”
There are other reasons for creating IDs, however. When you have a unique identifier, you can refer to it in other contexts. This is the “relation” in “relational model” — you tell your database that two pieces of content relate to each other by storing their IDs.
Suppose we had some users:

We can add authorship information to our nodes simply by embedding the user ID:
Now we’ve added authorship information right to our nodes. Simple, right?
Important Parts About the Relational Model That We (and Drupal) Glossed Over
Savvier readers will note that I omitted a fairly important detail. While it is possible to merely add IDs from another table, it’s substantially better to declare what’s called a foreign key. In plain English, a foreign key changes our “User ID” column from “contains a number” to “contains an ID from the users table”. Now, when we create a new node, we have to ensure that the User ID provided is valid — that is to say, that it’s an ID assigned to a user. Ever find a form that let you type 9999 in as a zip code? It’s kind of like that.
The other — and even better — part about this is that we can now place constraints on what the database does when one of the two related items is changed. The definition of a foreign key allows an administrator to specify what happens, and while there are a few options, I’m going to list only two:
- Carry the deletion from one table to the other. This action is called “cascade.” In the example above, this means that if I deleted a user, all of the corresponding nodes would be deleted as well.
- Prevent any deletion from occurring. This is the “restrict” action and means that the delete cannot succeed if there are still rows referencing the row you wish to delete. For our node/user example, this means that the database should prevent deletion of a specific user unless they don’t have any content associated with them. Typically, this type of action would be used if administrators need to either archive content or simply, as a sanity check, to prevent a lot of data from accidentally disappearing.
Why Doesn’t Drupal Use This?
As far as I can tell, there are two main reasons:
- Drupal intends to be agnostic of data storage. The relational model isn’t the only storage system out there, and engines for documents, objects, graphs, and columns do exist.
- When Drupal does use a relational database, it stores all field data in one database table, even if the field is shared among multiple entity types.
The problem with #2 is that the relational model mandates that if you have an “ID” column referencing another table, it can’t reference more than one table. Drupal simply stores the entity type and its ID in the table. Here’s a highly simplified “title” field database table:

What Are the Implications?
Drupal takes care of most of the ways in which the above scenario could break down. If you delete an entity, Drupal knows how fields are related to it and is able to clean those up.
Until, that is, we get to entity references. Let’s suppose we have a “like” field that allows users to like a particular node. Our database would have something like this:

We can see that user one has liked two posts, and user 88 has liked one. The trouble arises from this fact: Drupal only knows about the relationship between the user entities and the field data. Notice something absent from that statement? How about the relationship between user entities and the liked nodes?
If I deleted node 31, the last row would still be present. The database only knows that the column named “Liked Node” is a number. In a lot of cases, this isn’t too damaging. But, imagine a scenario where you’re feeding this data to an external service, such as one that provides automatic faceting. You might find that it doesn’t know to double check that all the IDs it passed actually exist.
What This All Means
Dear readers, this is why you sometimes go to a site, and when you’re filtering search results, you might see this:

That miscellaneous number there? It’s the ghost of a taxonomy term that someone deleted.
There are a number of issues about this very problem but still no solution in sight. Until then, I recommend field_reference_delete. It’s served us very well on an extremely high-traffic site. For more questions on how to do this, feel free to contact me!